


Understanding OpenAI’s transformer debugger with Mutable.ai Auto Wiki, while I make dinner
Understanding OpenAI’s transformer debugger with Mutable.ai Auto Wiki, while I make dinner
Can I understand OpenAI's new library to debug transformers while I make dinner? Let's find out.

OpenAI has open-sourced a tool for understanding transformer internals, which can be found at https://github.com/openai/transformer-debugger. I want to understand this library while I make dinner (salmon tonight), so I'm going to do that in the quickest way I know how: by using Auto Wiki, which converts codebases into Wikipedia-style articles complete with diagrams and citations to the code.
Jumping directly into the code without AutoWiki (the “old fashioned” way of understanding a repo) is slow going. There are hundreds of files in the repository. There is a readme and even a few videos to help me understand what is going on, but they only scratch the surface of the complexity here. Understanding this “raw” would be difficult even though this isn't a particularly large repository.
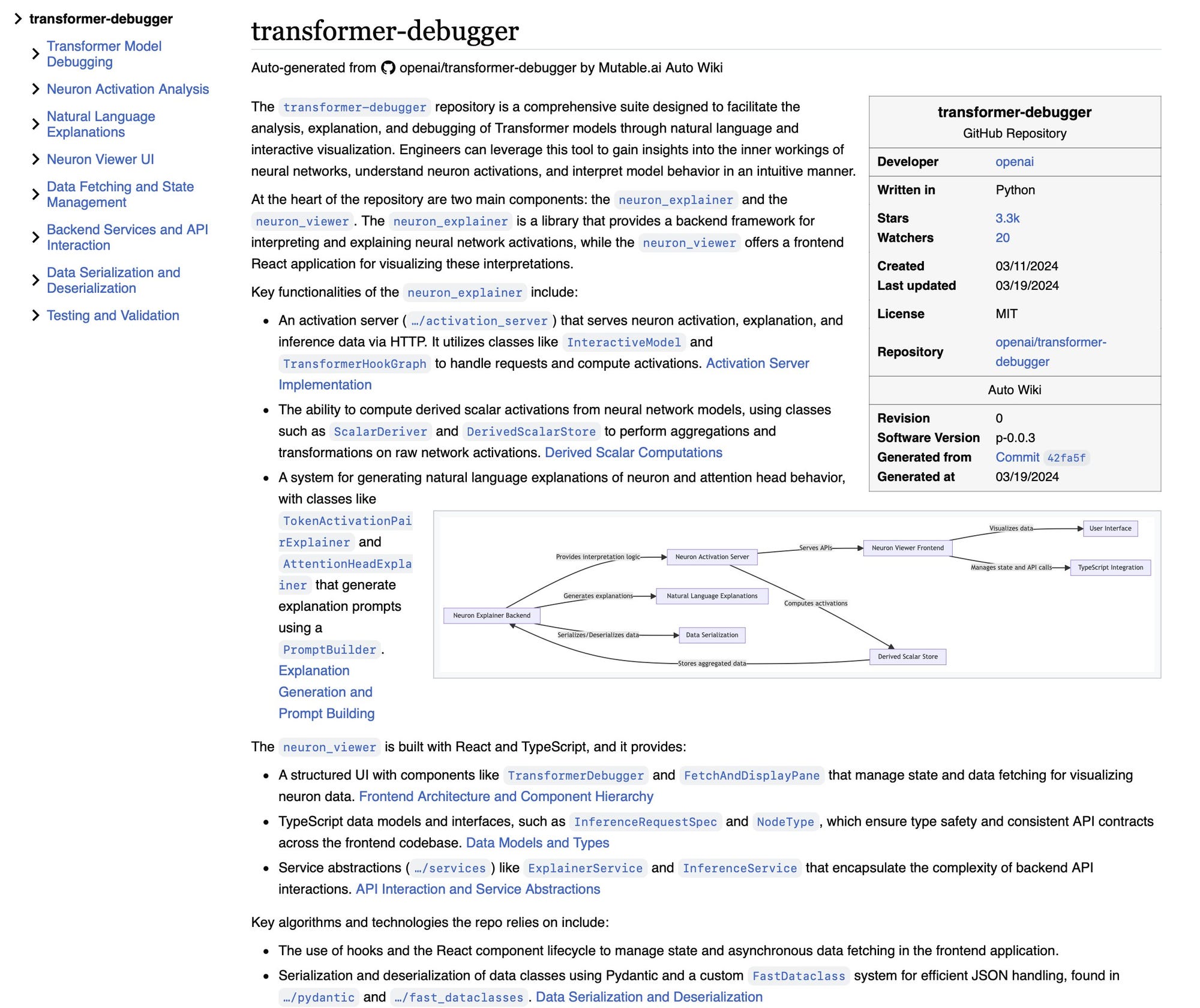
At this point, it's much easier to simply generate an auto wiki and use that to get my bearings.

At first glance, it appears that there is a backend that retrieves activations, explanations, and inference data, which is then visualized on a frontend. Sweet!
From here, we have a few options: diving into the backend or the frontend. I know OpenAI has mentioned that we can use it to ablate individual neurons and see what changes. Let's see how that might come about.

I used our filter to quickly find a section on the Visualization of Model Inferences and Node Metrics.

It seems like `AblateNodeSpecs` would be pretty important, so I'm jumping to that.
Jumping into the code, it seems like they have side-by-side panes with differing parameters corresponding to the ablation. Interesting...
Salmon is looking good btw, olive oil on low burn, this is way.

This piqued my interest in how they're displaying this info, so I'm going to check out this code and maybe later look at some actual demos they've put together (most codebases don't have demos going along with them!)

It appears there is a:
Logits display
Token effect display with color-coded tokens
Node display
I can already sort of picture this without even seeing the demo.
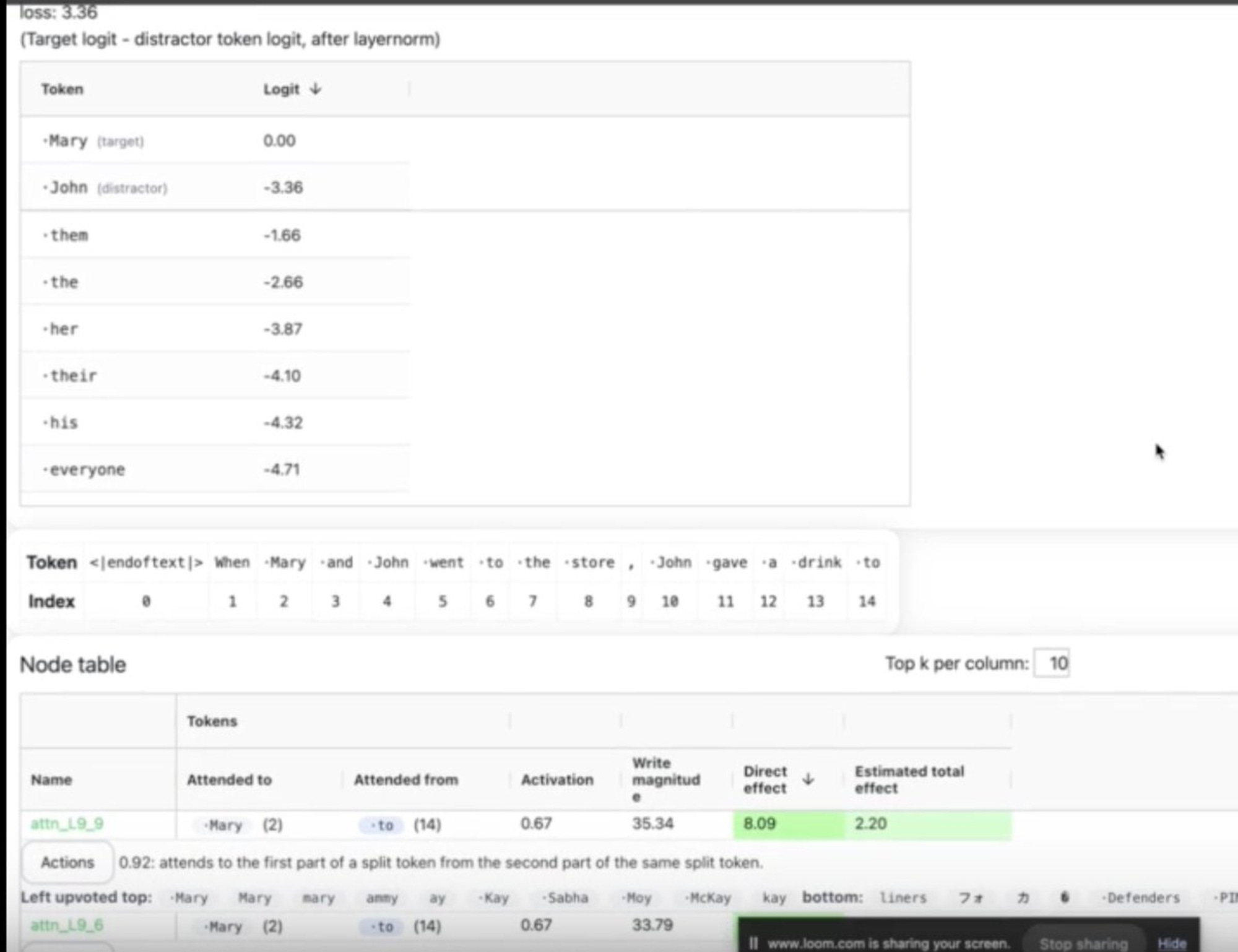
Okay, my curiosity got the better of me. I looked up the demo and indeed, these are the three central components of the display.
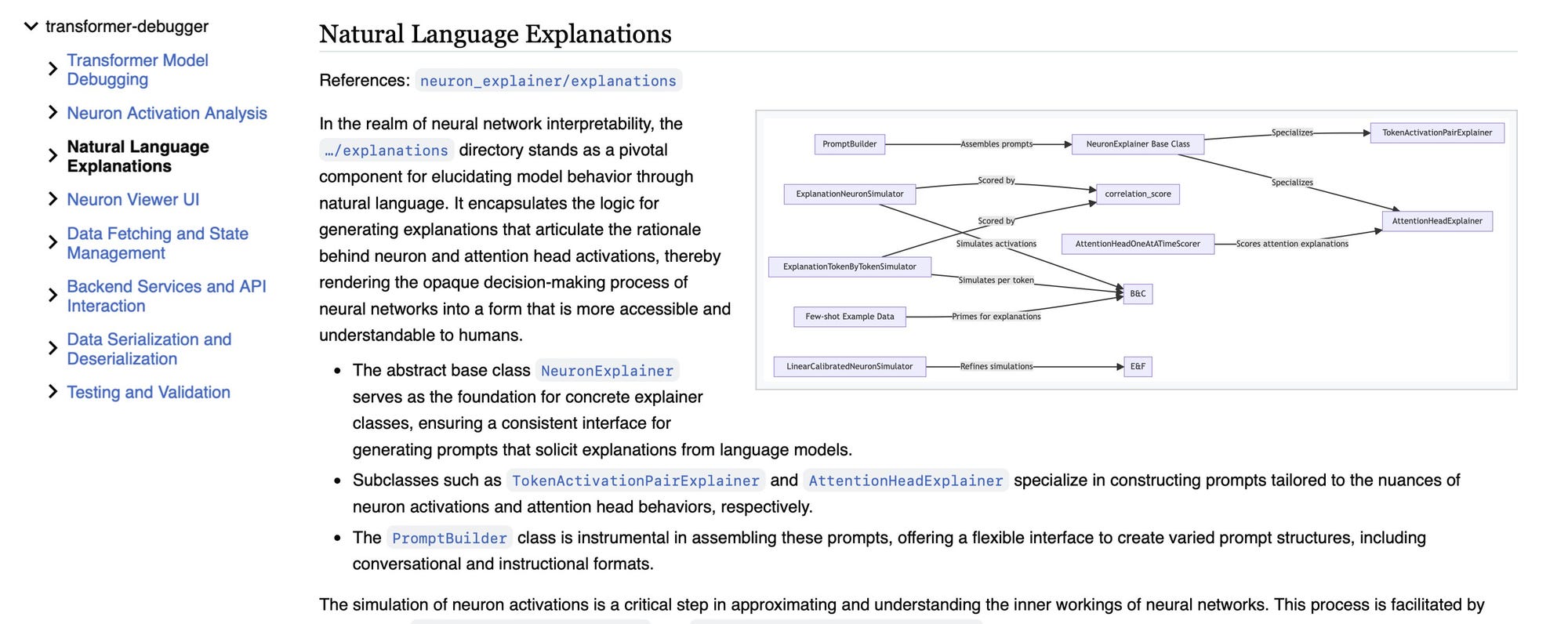
I noticed in the first pass of the wiki that there is a section on "Natural Language Explanations" https://wiki.mutable.ai/openai/transformer-debugger#natural-language-explanations, so I am going to look into that a bit.
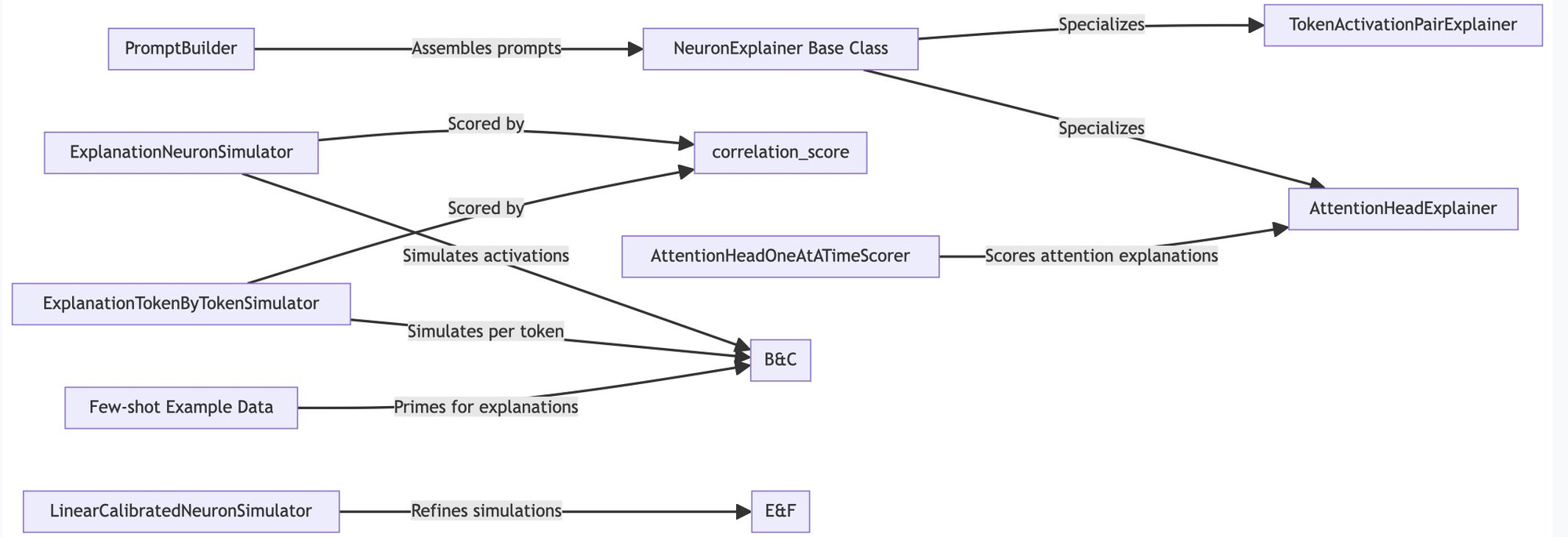

It seems to be doing this by:
Generating explanations
Simulating neural activations based on those explanations (using few shot prompting with examples of other explanations/activations)
Scoring and calibrating the explanations based on how closely the predicted activations match the actual activations
Finally, there is some example data. Nice!

I read a brief description of each section. Scoring and calibration seem very straightforward to me, so I'm going to skip reading more on this for now and dive into the others.

Focusing on explanation generation, I'm going to look at the TokenActivationPairExplainer.
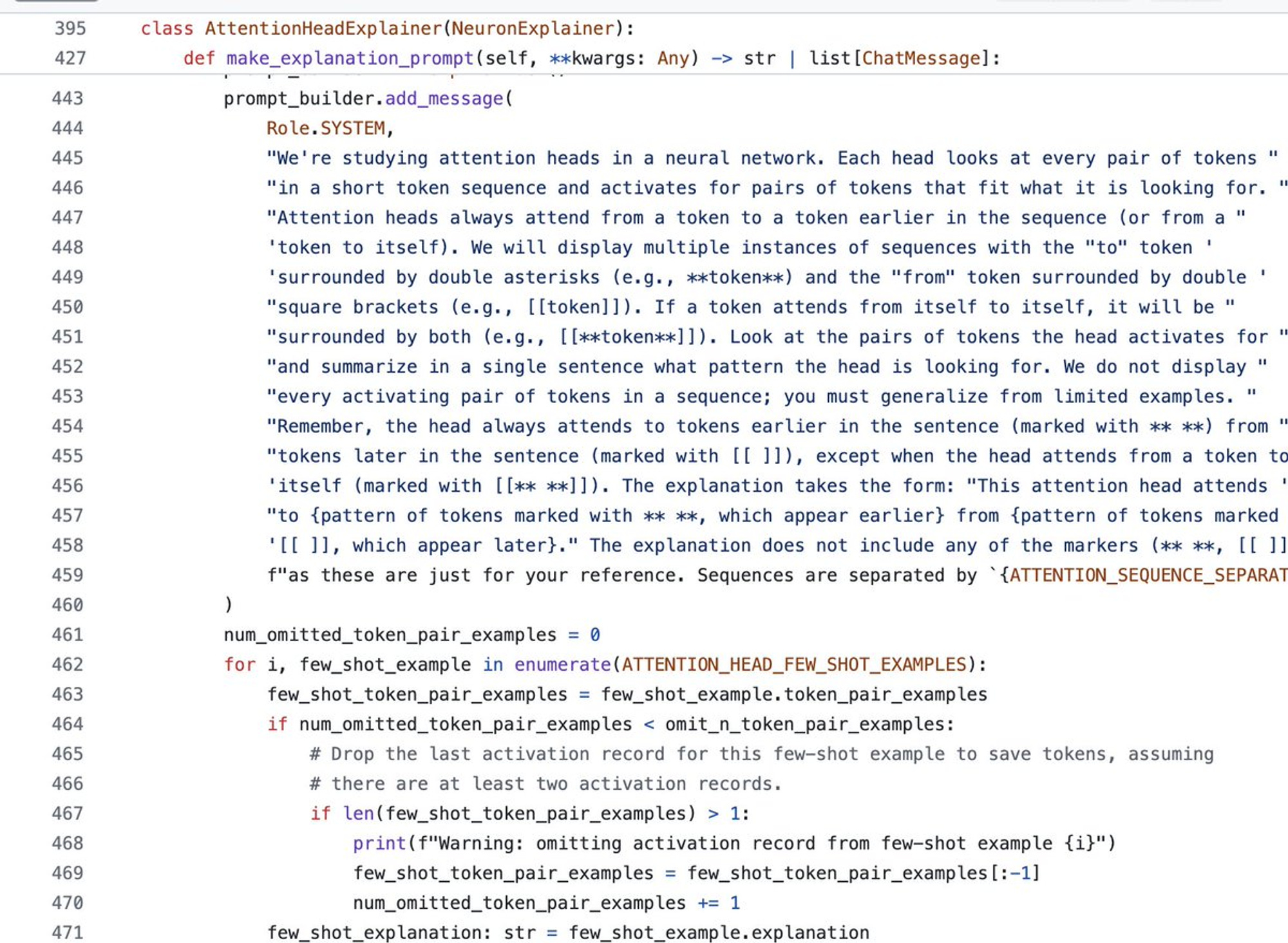
It seems like abstract builder classes, but upon scrolling down, I noticed that AttentionHeadExplainer has some more substantial content... interesting!
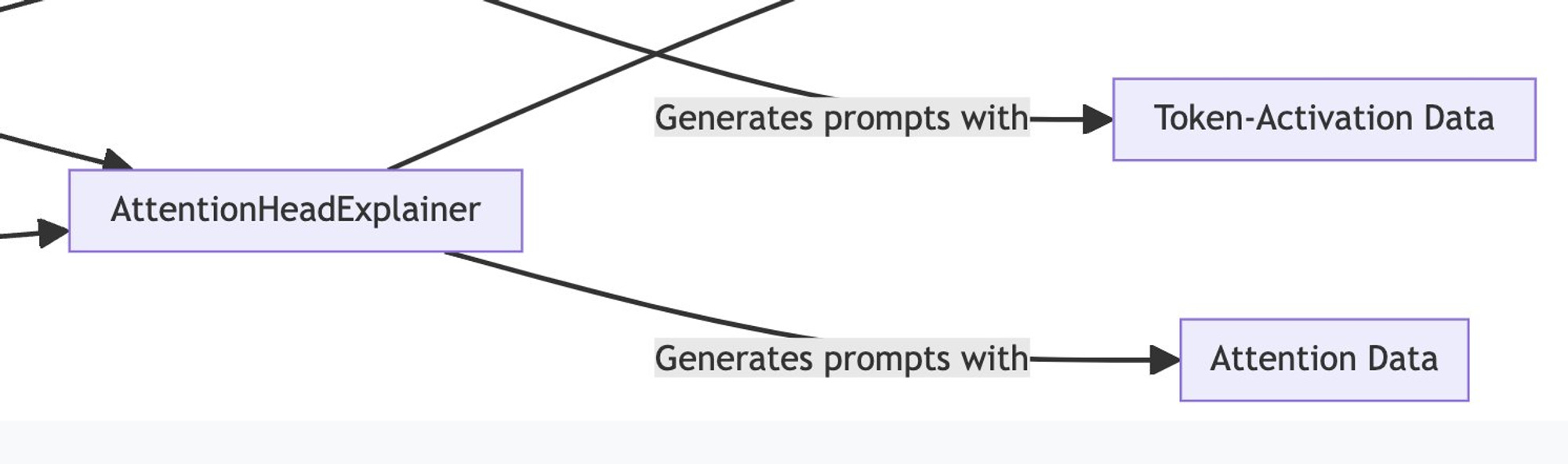
That prompt is very interesting and makes me want to see some of the input data.

Thankfully, we have a subsection on this here.


Going to explore ORIGINAL_EXAMPLES in few_shot_examples.py.


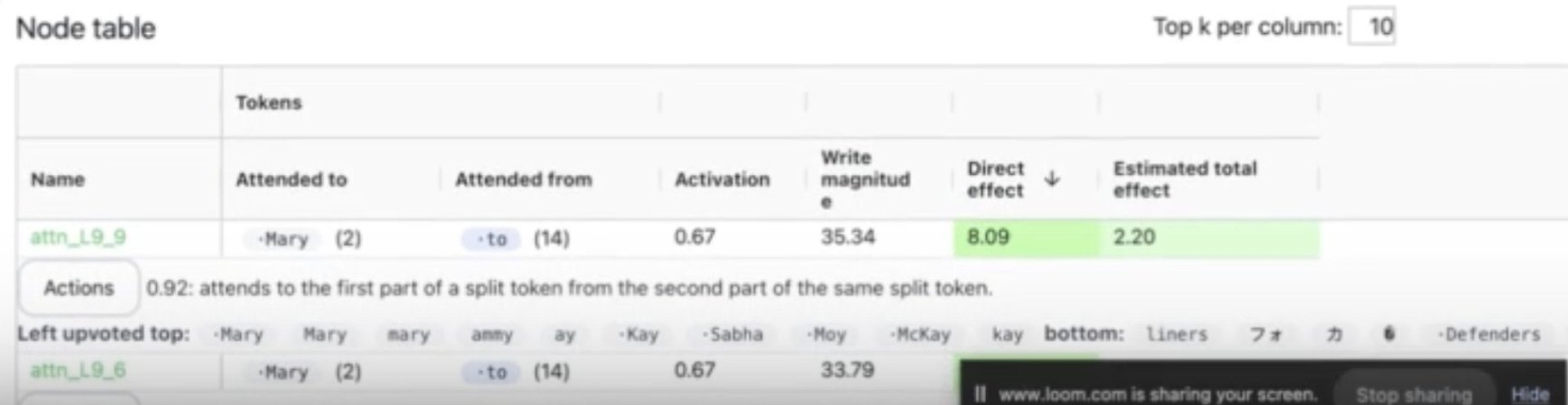

I now see how this data can create pairs that hydrate the prompt to generate the demo.

This would have taken me much longer otherwise, and the salmon looks ready now... time to eat!
We recently released Auto Wiki V2, which includes:
Filter and search for your wiki
AI revision with instruction
Manual edits to revise wikis
Learn more about Auto Wiki v2 here. We have more updates coming very soon, including auto updating wikis that stay up to date as the code changes. Thanks for reading!